
排查docker oomkillded问题
年前docker oomkilled 问题一直在困扰我们项目组,大致现象为java堆Xmx配置了6G,但运行一段时间后常驻内存RSS从5G逐渐增长到8G容器阈值,最后报出om killed 之后重启。因为我们业务对内存需求不是很迫切,所以占用8G内存明显不合理,所以之后有了一场漫长的排查问题之旅。
基础中的基础-JVM内存模型
开始逐步对堆外内存进行排查,首先了解一下JVM内存模型。根据JVM规范,JVM运行时数据区共分为虚拟机栈、堆、方法区、程序计数器、本地方法栈五个部分。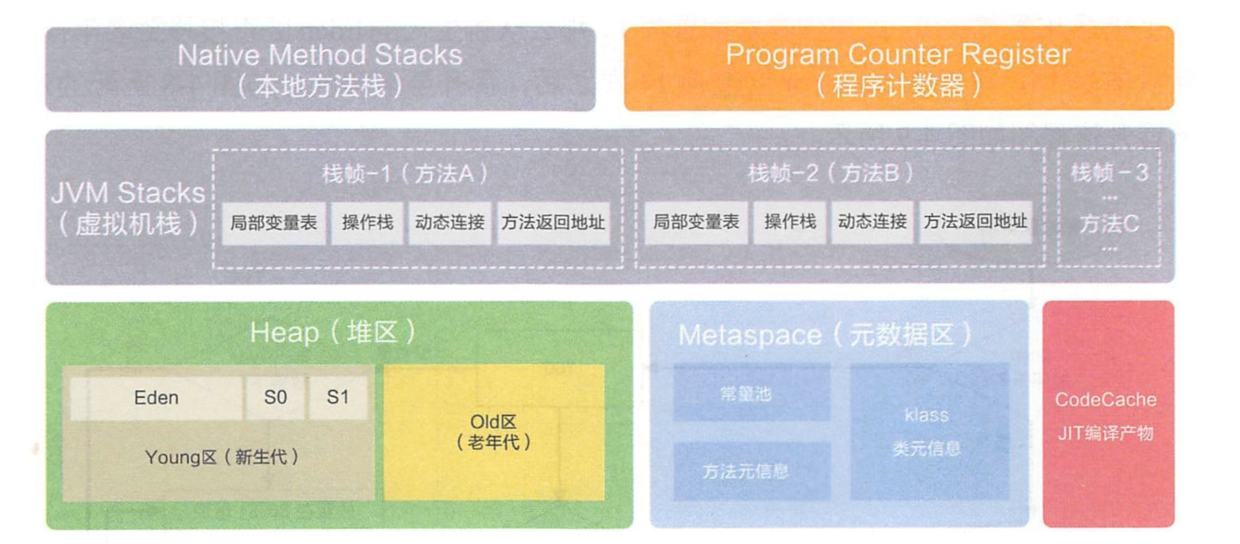 

PC 寄存器,也叫程序计数器。可以看成是当前线程所执行的字节码的行号指示器。不是重点。
虚拟机栈,描述Java方法执行的内存区域,它是线程私有的,栈帧在整个JVM体系中的地位颇高,包括局部变量表、操作栈、动态连接、方法返回地址等。当申请不到空间时,会抛出 OutOfMemoryError。
本地方法栈,和虚拟机栈实现的功能与抛出异常几乎相同。
堆内存。堆内存是 JVM 所有线程共享的部分,在虚拟机启动的时候就已经创建。所有的对象和数组都在堆上进行分配。这部分空间可通过 GC 进行回收。当申请不到空间时会抛出 OutOfMemoryError。
Metaspace(元空间)在JDK 1.8开始,方法区实现采用Metaspace代替,这些元数据信息直接使用本地内存来分配。元空间与永久代之间最大的区别在于:元空间不属于JVM使用的内存,而是使用(进程中的)直接内存。当申请不到空间时会抛出 OutOfMemoryError。
直接内存
java 8下是指除了Xmx设置的java堆外,java进程使用的其他内存。主要包括:DirectByteBuffer分配的内存,JNI里分配的内存,线程栈分配占用的系统内存,jvm本身运行过程分配的内存,codeCache,metaspace元数据空间。
JVM监控分析
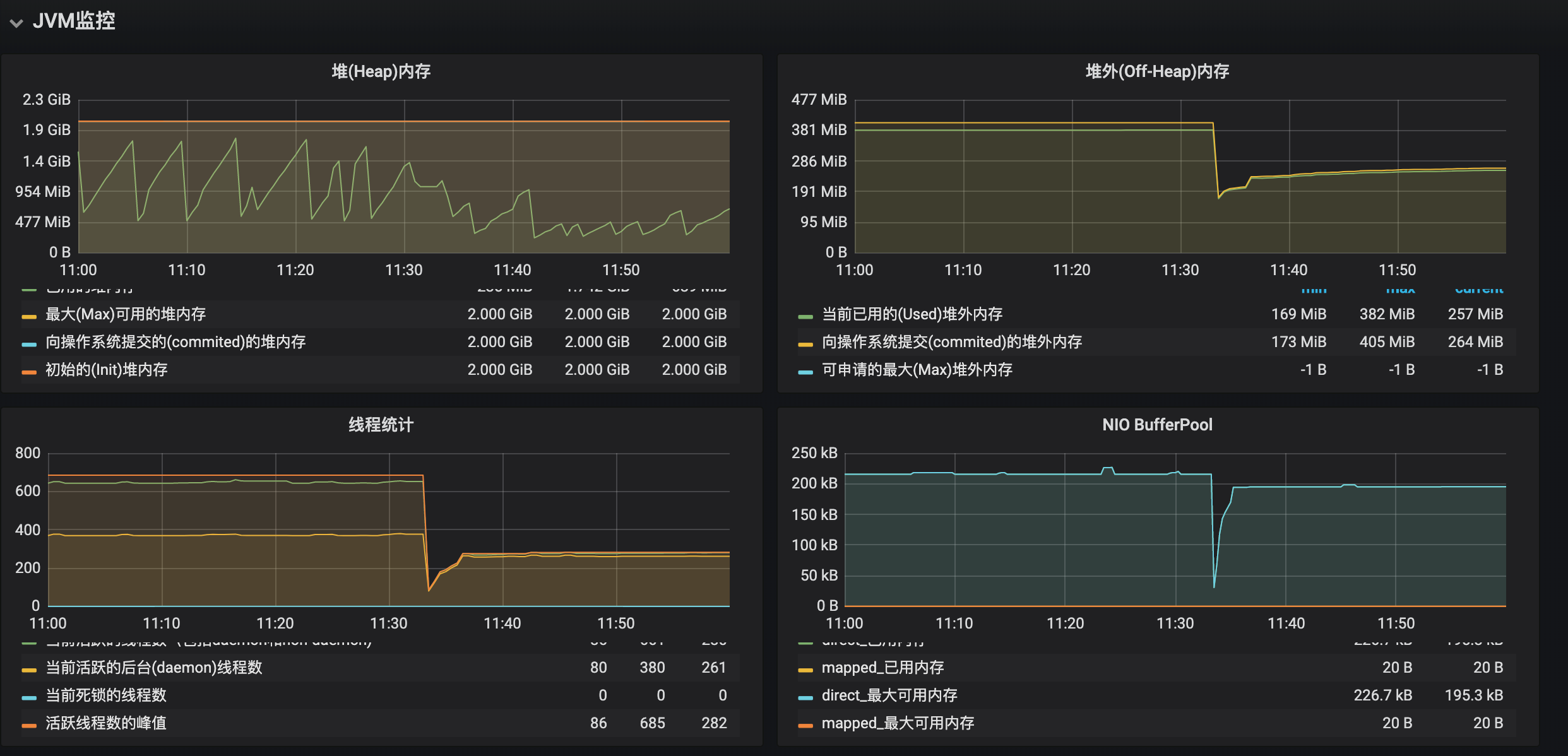
可以看到重启前堆内存、栈内存、元空间、直接内存占用空间都没有异常,多数问题通过监控就能定位大致方向,可惜这次监控大法没有生效,怀疑是JVM问题转向JVM原生内存使用方向排查。
使用NMT排查JVM原生内存使用
Native Memory Tracking(NMT)使用
NMT是Java7U40引入的HotSpot新特性,可用于监控JVM原生内存的使用,但比较可惜的是,目前的NMT不能监控到JVM之外或原生库分配的内存。java进程启动时指定开启NMT(有一定的性能损耗),输出级别可以设置为“summary”或“detail”级别。如:
1 | -XX:NativeMemoryTracking=summary 或者 |
开启后,通过jcmd可以访问收集到的数据。
1 | jcmd <pid> VM.native_memory [summary | detail | baseline | summary.diff | detail.diff |
如:jcmd 1 VM.native_memory,输出如下:
1 | Native Memory Tracking: |
- 保留内存(reserved):reserved memory 是指JVM 通过mmaped PROT_NONE 申请的虚拟地址空间,在页表中已经存在了记录(entries),保证了其他进程不会被占用,且保证了逻辑地址的连续性,能简化指针运算。
- 提交内存(commited):committed memory 是JVM向操做系统实际分配的内存(malloc/mmap),mmaped PROT_READ | PROT_WRITE,仍然会page faults,但是跟 reserved 不同,完全内核处理像什么也没发生一样。
这里需要注意的是:由于malloc/mmap的lazy allocation and paging机制,即使是commited的内存,也不一定会真正分配物理内存。
malloc/mmap is lazy unless told otherwise. Pages are only backed by physical memory once they’re accessed.
Tips:由于内存是一直在缓慢增长,因此在使用NMT跟踪堆外内存时,一个比较好的办法是,先建立一个内存使用基线,一段时间后再用当时数据和基线进行差别比较,这样比较容易定位问题。
1 | jcmd 1 VM.native_memory baseline |
同时pmap看一下物理内存的分配,RSS占用了10G。
1 | pmap -x 1 | sort -n -k3 |
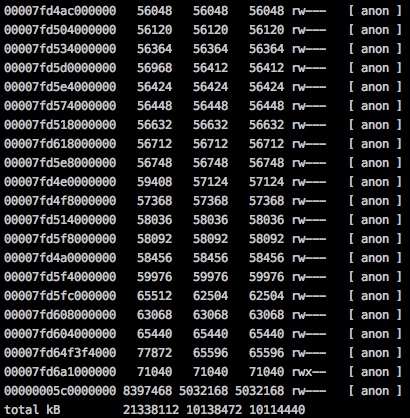 

运行一段时间后,做一下summary级别的diff,看下内存变化,同时再次pmap看下RSS增长情况。
1 | jcmd 1 VM.native_memory summary.diff |
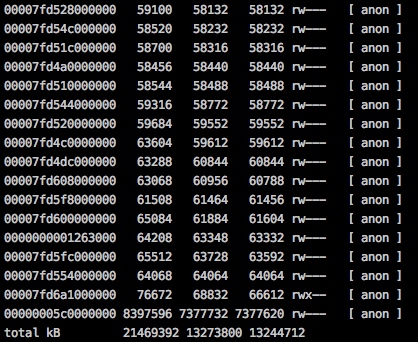 

发现这段时间pmap看到的RSS增长了3G多,但NMT观察到的内存增长了不到120M,还有大概2G多常驻内存不知去向,因此也基本排除了由于JVM自身管理的堆外内存的嫌疑。
gdb分析内存块内容
上面提到使用pmap来查看进程的内存映射,pmap命令实际是读取了/proc/pid/maps和/porc/pid/smaps文件来输出。发现一个细节,pmap取出的内存映射发现很多64M大小的内存块。这种内存块逐渐变多且占用的RSS常驻内存也逐渐增长到reserved保留内存大小,内存增长的2G多基本上也是由于这些64M的内存块导致的,因此看一下这些内存块里具体内容。
pmap -x 1看一下实际内存分配情况: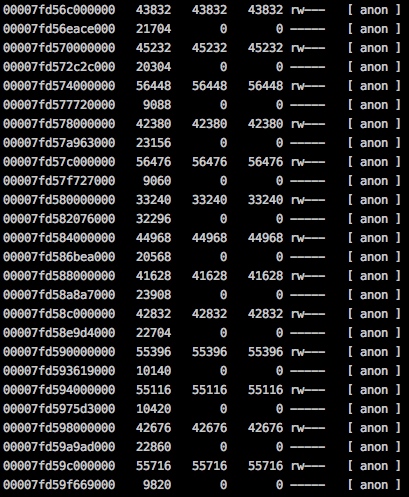 

找一块内存块进行dump:
1 | gdb --batch --pid 1 -ex "dump memory a.dump 0x7fd488000000 0x7fd488000000+56124000" |
简单分析一下内容,发现绝大部分是乱码的二进制内容,看不出什么问题。
strings a.dump | less
或者: hexdump -C a.dump | less
或者: view a.dump
没啥思路的时候,随便搜了一下发现貌似很多人碰到这种64M内存块的问题,了解到glibc的内存分配策略在高版本有较大调整:
从glibc 2.11(为应用系统在多核心CPU和多Sockets环境中高伸缩性提供了一个动态内存分配的特性增强)版本开始引入了per thread arena内存池,Native Heap区被打散为sub-pools ,这部分内存池叫做Arena内存池。也就是说,以前只有一个main arena,目前是一个main arena(还是位于Native Heap区) + 多个per thread arena,多个线程之间不再共用一个arena内存区域了,保证每个线程都有一个堆,这样避免内存分配时需要额外的锁来降低性能。main arena主要通过brk/sbrk系统调用去管理,per thread arena主要通过mmap系统调用去分配和管理。
一个32位的应用程序进程,最大可创建 2 CPU总核数个arena内存池(MALLOC_ARENA_MAX),每个arena内存池大小为1MB,一个64位的应用程序进程,最大可创建 8 CPU总核数个arena内存池(MALLOC_ARENA_MAX),每个arena内存池大小为64MB
ptmalloc2内存分配和释放
当某一线程需要调用 malloc()分配内存空间时, 该线程先查看线程私有变量中是否已经存在一个分配区,如果存在, 尝试对该分配区加锁,如果加锁成功,使用该分配区分配内存,如果失败, 该线程搜索循环链表试图获得一个没有加锁的分配区。如果所有的分配区都已经加锁,那么 malloc()会开辟一个新的分配区,把该分配区加入到全局分配区循环链表并加锁,然后使用该分配区进行分配内存操作。在释放操作中,线程同样试图获得待释放内存块所在分配区的锁,如果该分配区正在被别的线程使用,则需要等待直到其他线程释放该分配区的互斥锁之后才可以进行释放操作。用户 free 掉的内存并不是都会马上归还给系统,ptmalloc2 会统一管理 heap 和 mmap 映射区域中的空闲的chunk,当用户进行下一次分配请求时, ptmalloc2 会首先试图在空闲的chunk 中挑选一块给用户,这样就避免了频繁的系统调用,降低了内存分配的开销。
ptmalloc2的内存收缩机制
业务层调用free方法释放内存时,ptmalloc2先判断 top chunk 的大小是否大于 mmap 收缩阈值(默认为 128KB),如果是的话,对于主分配区,则会试图归还 top chunk 中的一部分给操作系统。但是最先分配的 128KB 空间是不会归还的,ptmalloc 会一直管理这部分内存,用于响应用户的分配 请求;如果为非主分配区,会进行 sub-heap 收缩,将 top chunk 的一部分返回给操 作系统,如果 top chunk 为整个 sub-heap,会把整个 sub-heap 还回给操作系统。做 完这一步之后,释放结束,从 free() 函数退出。可以看出,收缩堆的条件是当前 free 的 chunk 大小加上前后能合并 chunk 的大小大于 64k,并且要 top chunk 的大 小要达到 mmap 收缩阈值,才有可能收缩堆。
ptmalloc2的mmap分配阈值动态调整
M_MMAP_THRESHOLD 用于设置 mmap 分配阈值,默认值为 128KB,ptmalloc 默认开启 动态调整 mmap 分配阈值和 mmap 收缩阈值。当用户需要分配的内存大于 mmap 分配阈值,ptmalloc 的 malloc()函数其实相当于 mmap() 的简单封装,free 函数相当于 munmap()的简单封装。相当于直接通过系统调用分配内存, 回收的内存就直接返回给操作系统了。因为这些大块内存不能被 ptmalloc 缓存管理,不能重用,所以 ptmalloc 也只有在万不得已的情况下才使用该方式分配内存。
如何优化解决
三种方案:
第一种:控制分配区的总数上限。默认64位系统分配区数为:cpu核数*8,如当前环境40核系统分配区数为320个,每个64M上限的话最多可达20G,限制上限后,后续不够的申请会直接走mmap分配和munmap回收,不会进入ptmalloc2的buffer池。
所以第一种方案调整一下分配池上限个数到4:
1 | export MALLOC_ARENA_MAX=4 |
第二种:之前降到ptmalloc2默认会动态调整mmap分配阈值,因此对于较大的内存请求也会进入ptmalloc2的内存buffer池里,这里可以去掉ptmalloc的动态调整功能。可以设置 M_TRIM_THRESHOLD,M_MMAP_THRESHOLD,M_TOP_PAD 和 M_MMAP_MAX 中的任意一个。这里可以固定分配阈值为128K,这样超过128K的内存分配请求都不会进入ptmalloc的buffer池而是直接走mmap分配和munmap回收(性能上会有损耗):
1 | export MALLOC_MMAP_THRESHOLD_=131072 |
第三种:使用tcmalloc来替代默认的ptmalloc2。google的tcmalloc提供更优的内存分配效率,性能更好,ThreadCache会阶段性的回收内存到CentralCache里。 解决了ptmalloc2中arena之间不能迁移导致内存浪费的问题。
总结收获
定位问题,一定要了解问题的领域范围,在这次排查中,定位OOM问题领域顺序就是 jvm内存 -> jvm内部内存 -> 进程内存。
操作系统知识不能丢,扎实的基础知识可以节省非常多百度的时间和推理问题的时间
知识领域是相同的,比如这次的ptmalloc内存分配基本原理和metaspace内存分配、netty的内存分配原理非常相似
当时排查问题时因为已经定位到是内存分配问题,所以没有留下问题排查中间过程的相关数据。最近偶然看到一篇博客的记录和我的经历极为相似,于是我参考博客和自己的排查经验整合了这篇排查问题记录。结果和过程都很重要,只有结果,没有过程容易招致他人的不理解,能被人理解也是一门学问~
