
消息队列提供的功能
- 异步处理
- 流量控制
- 消息解耦
队列和主题的区别
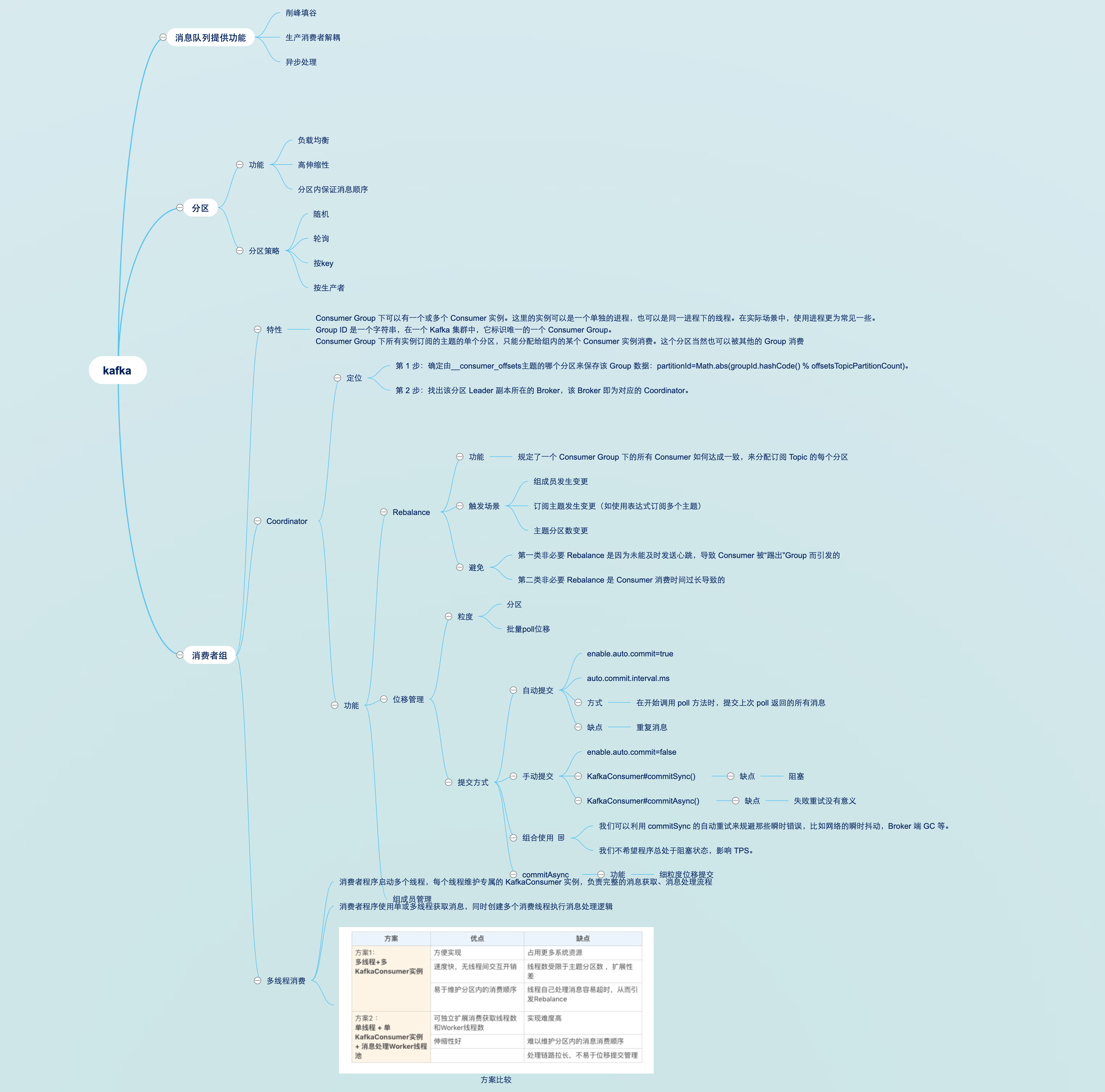
最初的消息队列,就是一个严格意义上的队列。在计算机领域,“队列(Queue)”是一种数据结构,有完整而严格的定义。在维基百科中,队列的定义是这样的:
队列是先进先出(FIFO, First-In-First-Out)的线性表(Linear List)。在具体应用中通常用链表或者数组来实现。队列只允许在后端(称为 rear)进行插入操作,在前端(称为 front)进行删除操作。
**早期的消息队列,就是按照“队列”的数据结构来设计的。**我们一起看下这个图,生产者(Producer)发消息就是入队操作,消费者(Consumer)收消息就是出队也就是删除操作,服务端存放消息的容器自然就称为“队列”。
这就是最初的一种消息模型:队列模型。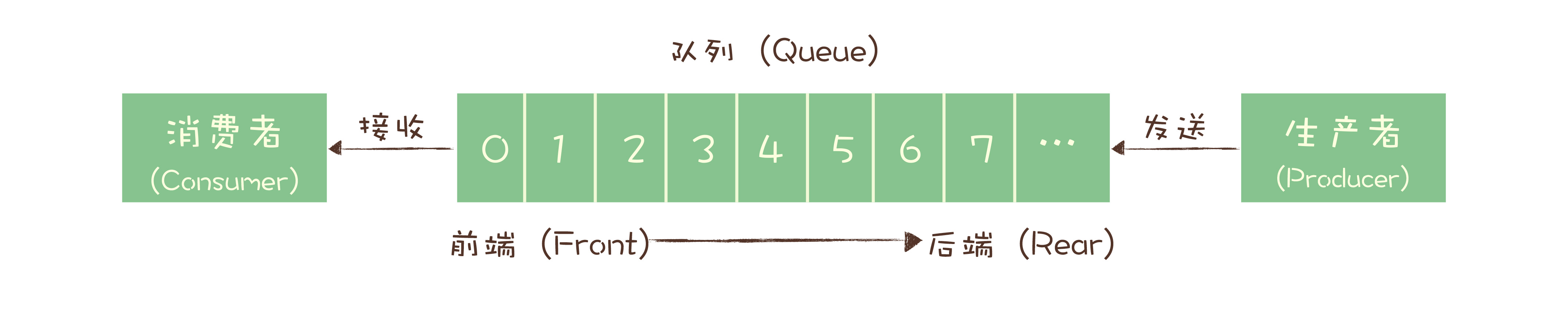
如果需要将一份消息数据分发给多个消费者,要求每个消费者都能收到全量的消息,例如,对于一份订单数据,风控系统、分析系统、支付系统等都需要接收消息。这个时候,单个队列就满足不了需求,一个可行的解决方式是,为每个消费者创建一个单独的队列,让生产者发送多份。
为了解决这个问题,演化出了另外一种消息模型:“发布 - 订阅模型(Publish-Subscribe Pattern)”。
在发布 - 订阅模型中,消息的发送方称为发布者(Publisher),消息的接收方称为订阅者(Subscriber),服务端存放消息的容器称为主题(Topic)。发布者将消息发送到主题中,订阅者在接收消息之前需要先“订阅主题”。“订阅”在这里既是一个动作,同时还可以认为是主题在消费时的一个逻辑副本,每份订阅中,订阅者都可以接收到主题的所有消息。
保障消息队列不丢失
其实,现在主流的消息队列产品都提供了非常完善的消息可靠性保证机制,完全可以做到在消息传递过程中,即使发生网络中断或者硬件故障,也能确保消息的可靠传递,不丢消息。
绝大部分丢消息的原因都是由于开发者不熟悉消息队列,没有正确使用和配置消息队列导致的。虽然不同的消息队列提供的 API 不一样,相关的配置项也不同,但是在保证消息可靠传递这块儿,它们的实现原理是一样的。
检测消息丢失的方法
- 分布式链路跟踪系统
- 根据生产者标示+分区号+递增消息号判断
- 生产者保存需要核对是否丢失的数据,消费者消费完之后需要与生产者核对数据
像 Kafka 和 RocketMQ 这样的消息队列,它是不保证在 Topic 上的严格顺序的,只能保证分区上的消息是有序的,所以我们在发消息的时候必须要指定分区,并且,在每个分区单独检测消息序号的连续性。
如果你的系统中 Producer 是多实例的,由于并不好协调多个 Producer 之间的发送顺序,所以也需要每个 Producer 分别生成各自的消息序号,并且需要附加上 Producer 的标识,在 Consumer 端按照每个 Producer 分别来检测序号的连续性。
Consumer 实例的数量最好和分区数量一致,做到 Consumer 和分区一一对应,这样会比较方便地在 Consumer 内检测消息序号的连续性。
如何确保消息不丢失
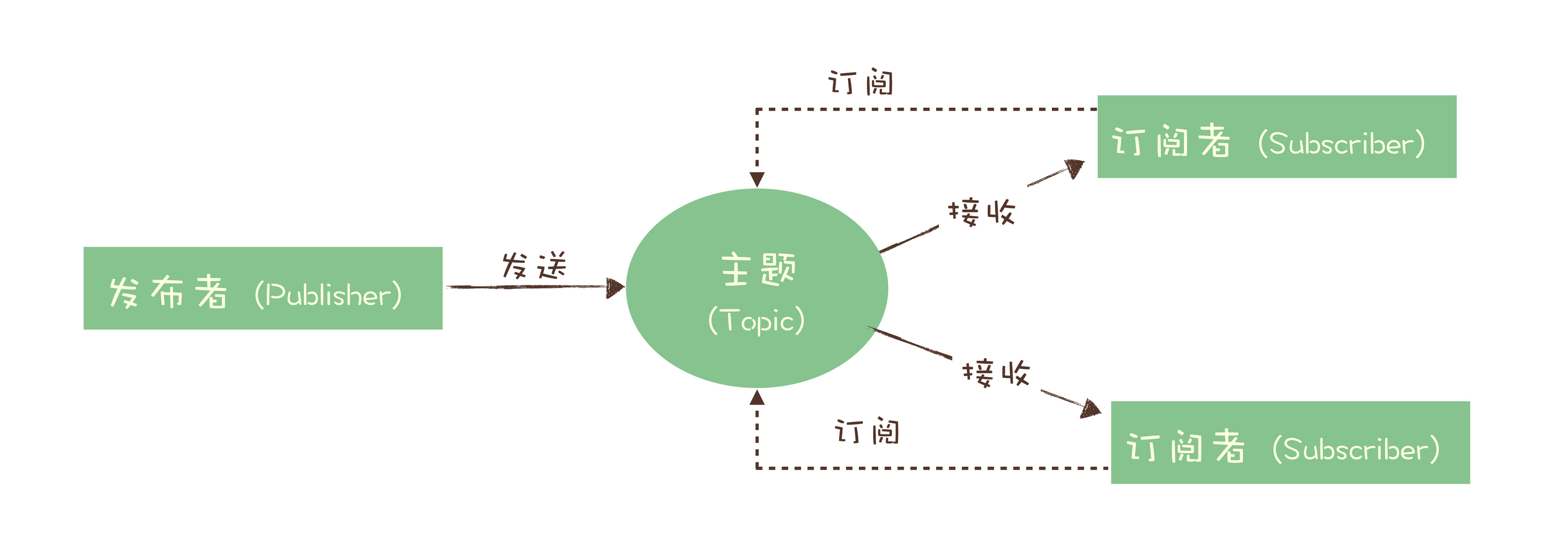
一条消息从生产到消费完成这个过程,可以划分三个阶段:
生产阶段
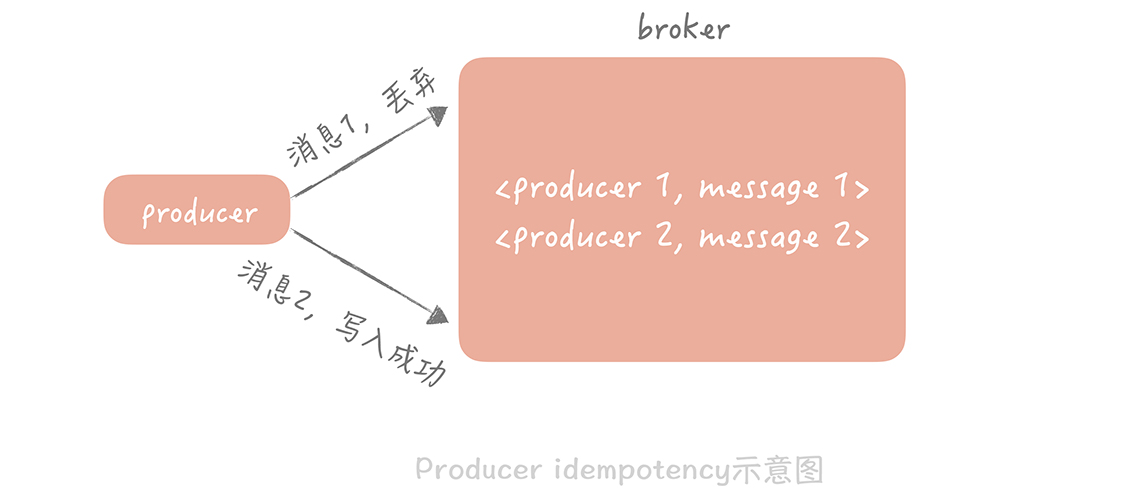
在生产阶段,消息队列通过最常用的请求确认机制,来保证消息的可靠传递:当你的代码调用发消息方法时,消息队列的客户端会把消息发送到 Broker,Broker 收到消息后,会给客户端返回一个确认响应,表明消息已经收到了。客户端收到响应后,完成了一次正常消息的发送。
只要 Producer 收到了 Broker 的确认响应,就可以保证消息在生产阶段不会丢失。有些消息队列在长时间没收到发送确认响应后,会自动重试,如果重试再失败,就会以返回值或者异常的方式告知用户。
你在编写发送消息代码时,需要注意,正确处理返回值或者捕获异常,就可以保证这个阶段的消息不会丢失。
存储阶段
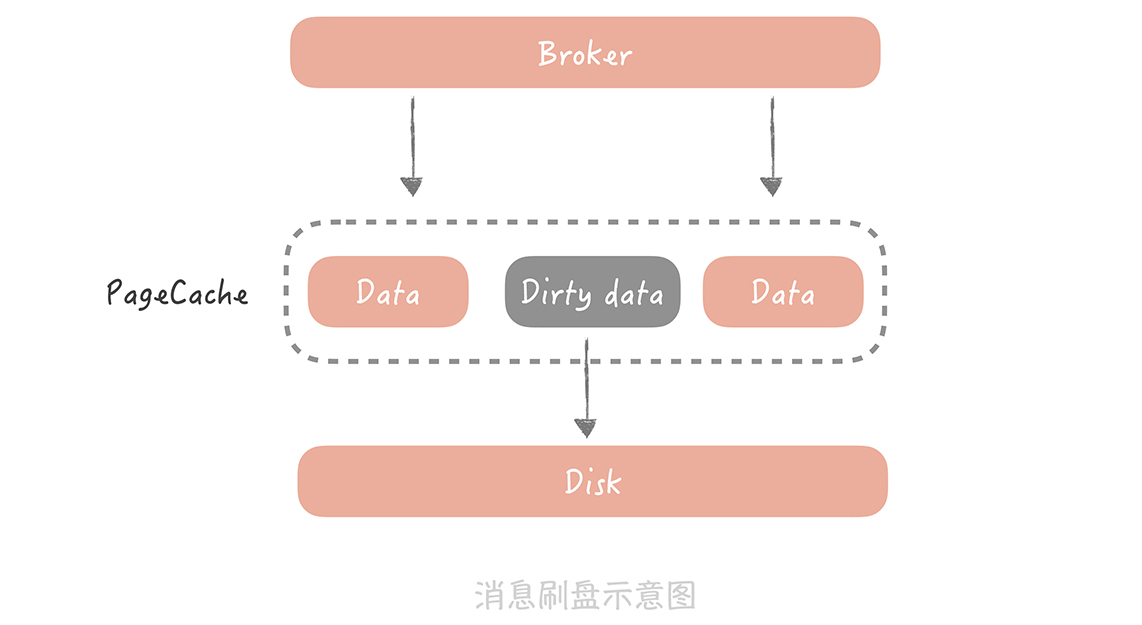
在存储阶段正常情况下,只要 Broker 在正常运行,就不会出现丢失消息的问题,但是如果 Broker 出现了故障,比如进程死掉了或者服务器宕机了,还是可能会丢失消息的。
如果对消息的可靠性要求非常高,可以通过配置 Broker 参数来避免因为宕机丢消息。
对于单个节点的 Broker,需要配置 Broker 参数,在收到消息后,将消息写入磁盘后再给 Producer 返回确认响应,这样即使发生宕机,由于消息已经被写入磁盘,就不会丢失消息,恢复后还可以继续消费。例如,在 RocketMQ 中,需要将刷盘方式 flushDiskType 配置为 SYNC_FLUSH 同步刷盘。
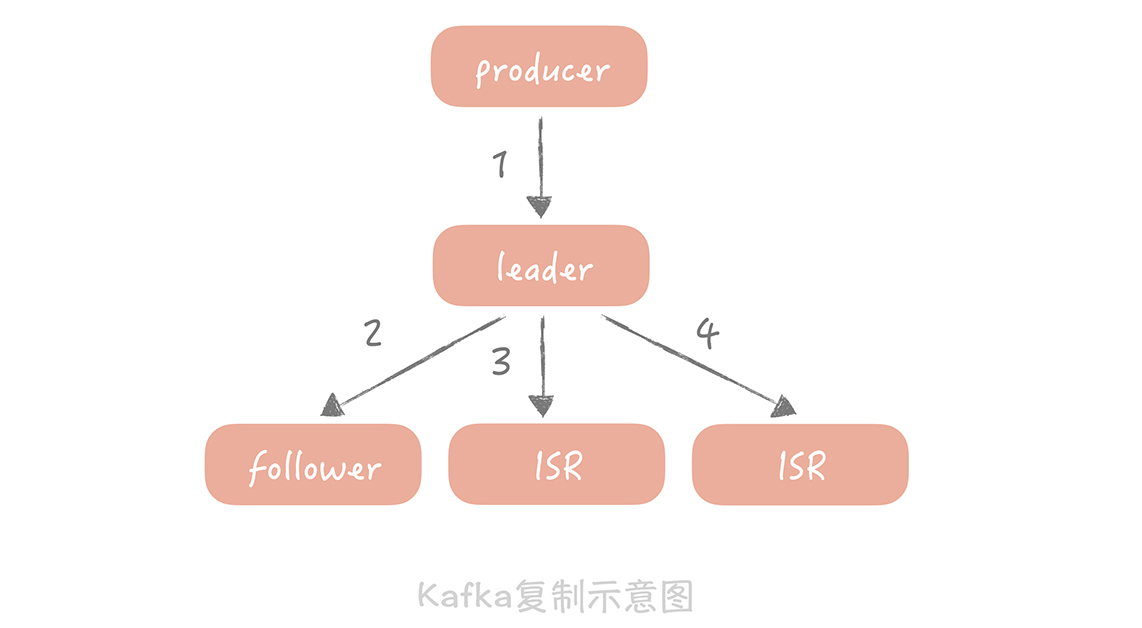
如果是 Broker 是由多个节点组成的集群,需要将 Broker 集群配置成:至少将消息发送到 2 个以上的节点,再给客户端回复发送确认响应。这样当某个 Broker 宕机时,其他的 Broker 可以替代宕机的 Broker,也不会发生消息丢失。
消费阶段
消费阶段采用和生产阶段类似的确认机制来保证消息的可靠传递,客户端从 Broker 拉取消息后,执行用户的消费业务逻辑,成功后,才会给 Broker 发送消费确认响应。如果 Broker 没有收到消费确认响应,下次拉消息的时候还会返回同一条消息,确保消息不会在网络传输过程中丢失,也不会因为客户端在执行消费逻辑中出错导致丢失。
你在编写消费代码时需要注意的是,不要在收到消息后就立即发送消费确认,而是应该在执行完所有消费业务逻辑之后,再发送消费确认。
对于kafka的相关使用可以参考之前的一篇文章【消息队列(一)-如何解决消息丢失】
解决消息重复问题
消息重复的情况必然存在
在 MQTT 协议中,给出了三种传递消息时能够提供的服务质量标准,这三种服务质量从低到高依次是:
- At most once: 至多一次。消息在传递时,最多会被送达一次。换一个说法就是,没什么消息可靠性保证,允许丢消息。一般都是一些对消息可靠性要求不太高的监控场景使用,比如每分钟上报一次机房温度数据,可以接受数据少量丢失。
- At least once: 至少一次。消息在传递时,至少会被送达一次。也就是说,不允许丢消息,但是允许有少量重复消息出现。
- Exactly once:恰好一次。消息在传递时,只会被送达一次,不允许丢失也不允许重复,这个是最高的等级。
这个服务质量标准不仅适用于 MQTT,对所有的消息队列都是适用的。我们现在常用的绝大部分消息队列提供的服务质量都是 At least once,包括 RocketMQ、RabbitMQ 和 Kafka 都是这样。也就是说,消息队列很难保证消息不重复。
利用幂等性解决重复消息问题
利用数据库的唯一约束实现幂等
不光是可以使用关系型数据库,只要是支持类似“INSERT IF NOT EXIST”语义的存储类系统都可以用于实现幂等,比如,你可以用 Redis 的 SETNX 命令来替代数据库中的唯一约束,来实现幂等消费。
为更新的数据设置前置条件
另外一种实现幂等的思路是,给数据变更设置一个前置条件,如果满足条件就更新数据,否则拒绝更新数据,在更新数据的时候,同时变更前置条件中需要判断的数据。这样,重复执行这个操作时,由于第一次更新数据的时候已经变更了前置条件中需要判断的数据,不满足前置条件,则不会重复执行更新数据操作。
但是,如果我们要更新的数据不是数值,或者我们要做一个比较复杂的更新操作怎么办?用什么作为前置判断条件呢?更加通用的方法是,给你的数据增加一个版本号属性,每次更数据前,比较当前数据的版本号是否和消息中的版本号一致,如果不一致就拒绝更新数据,更新数据的同时将版本号 +1,一样可以实现幂等更新。记录并检查操作
如果上面提到的两种实现幂等方法都不能适用于你的场景,还有一种通用性最强,适用范围最广的实现幂等性方法:记录并检查操作,也称为“Token 机制或者 GUID(全局唯一 ID)机制”,实现的思路特别简单:在执行数据更新操作之前,先检查一下是否执行过这个更新操作。
具体的实现方法是,在发送消息时,给每条消息指定一个全局唯一的 ID,消费时,先根据这个 ID 检查这条消息是否有被消费过,如果没有消费过,才更新数据,然后将消费状态置为已消费。
原理和实现是不是很简单?其实一点儿都不简单,在分布式系统中,这个方法其实是非常难实现的,在“检查消费状态,然后更新数据并且设置消费状态”中,三个操作必须作为一组操作保证原子性,才能真正实现幂等,否则就会出现 Bug。
对于这个问题,当然我们可以用事务来实现,也可以用锁来实现,但是在分布式系统中,无论是分布式事务还是分布式锁都是比较难解决问题。
对于kafka的相关使用可以参考之前的一篇文章【消息队列(二)-消息幂等】
处理消息积压
优化消息收发性能,预防消息积压的方法有两种,增加批量或者是增加并发,在发送端这两种方法都可以使用,在消费端需要注意的是,增加并发需要同步扩容分区数量,否则是起不到效果的。
对于系统发生消息积压的情况,需要先解决积压,再分析原因,毕竟保证系统的可用性是首先要解决的问题。快速解决积压的方法就是通过水平扩容增加 Consumer 的实例数量。