
缓存专题(二) Cache Aside(旁路缓存)策略
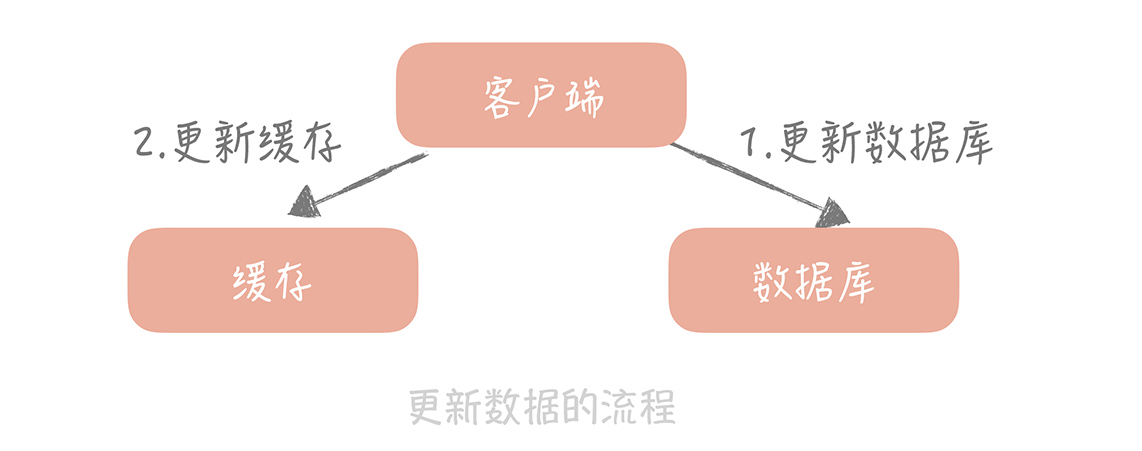
我们来考虑一种最简单的业务场景,比方说在你的电商系统中有一个用户表,表中只有 ID 和年龄两个字段,缓存中我们以 ID 为 Key 存储用户的年龄信息。那么当我们要把 ID 为 1 的用户的年龄从 19 变更为 20,要如何做呢?
你可能会产生这样的思路:先更新数据库中 ID 为 1 的记录,再更新缓存中 Key 为 1 的数据。
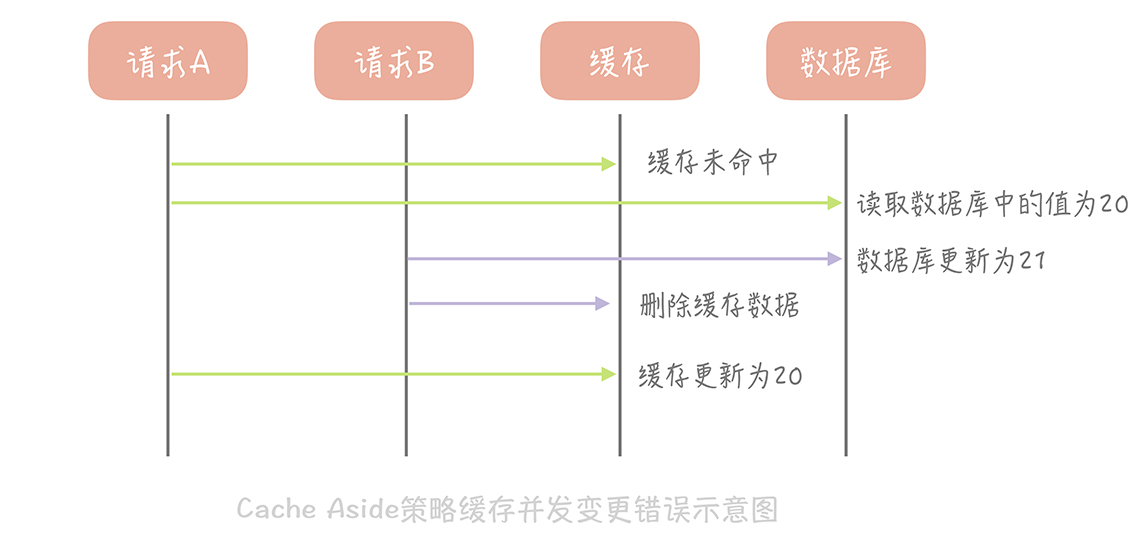
这个思路会造成缓存和数据库中的数据不一致。比如,A 请求将数据库中 ID 为 1 的用户年龄从 19 变更为 20,与此同时,请求 B 也开始更新 ID 为 1 的用户数据,它把数据库中记录的年龄变更为 21,然后变更缓存中的用户年龄为 21。紧接着,A 请求开始更新缓存数据,它会把缓存中的年龄变更为 20。此时,数据库中用户年龄是 21,而缓存中的用户年龄却是 20。
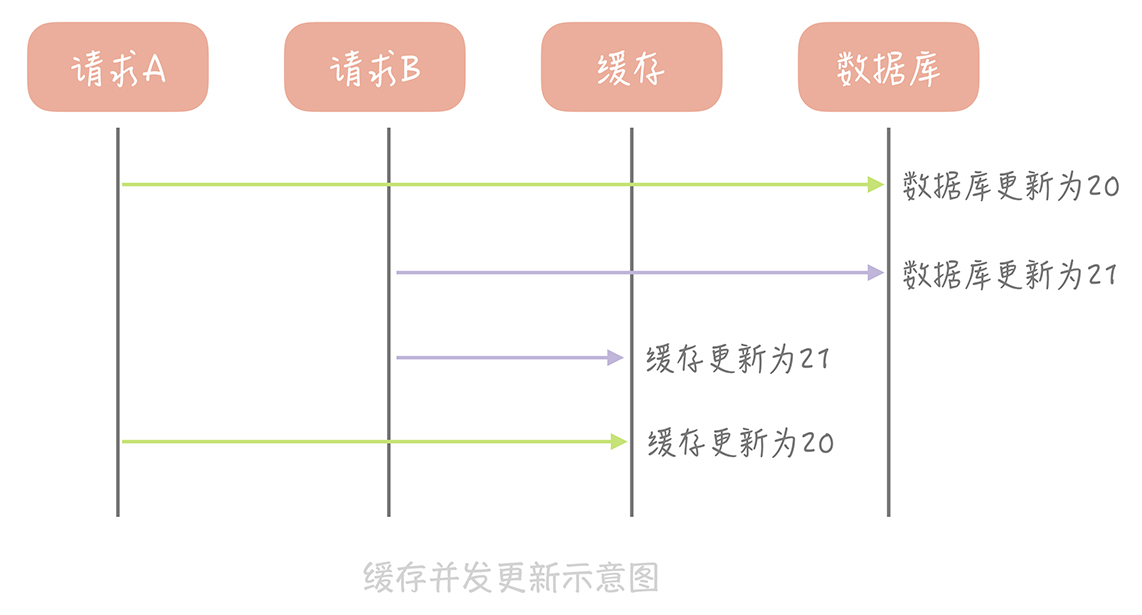
为什么产生这个问题呢?因为变更数据库和变更缓存是两个独立的操作,而我们并没有对操作做任何的并发控制。那么当两个线程并发更新它们的时候,就会因为写入顺序的不同造成数据的不一致。
另外,直接更新缓存还存在另外一个问题就是丢失更新。还是以我们的电商系统为例,假如电商系统中的账户表有三个字段:ID、户名和金额,这个时候缓存中存储的就不只是金额信息,而是完整的账户信息了。当更新缓存中账户金额时,你需要从缓存中查询完整的账户数据,把金额变更后再写入到缓存中。
这个过程中也会有并发的问题,比如说原有金额是 20,A 请求从缓存中读到数据,并且把金额加 1,变更成 21,在未写入缓存之前又有请求 B 也读到缓存的数据后把金额也加 1,也变更成 21,两个请求同时把金额写回缓存,这时缓存里面的金额是 21,但是我们实际上预期是金额数加 2,这也是一个比较大的问题。
那我们要如何解决这个问题呢?其实,我们可以在更新数据时不更新缓存,而是删除缓存中的数据,在读取数据时,发现缓存中没了数据之后,再从数据库中读取数据,更新到缓存中。
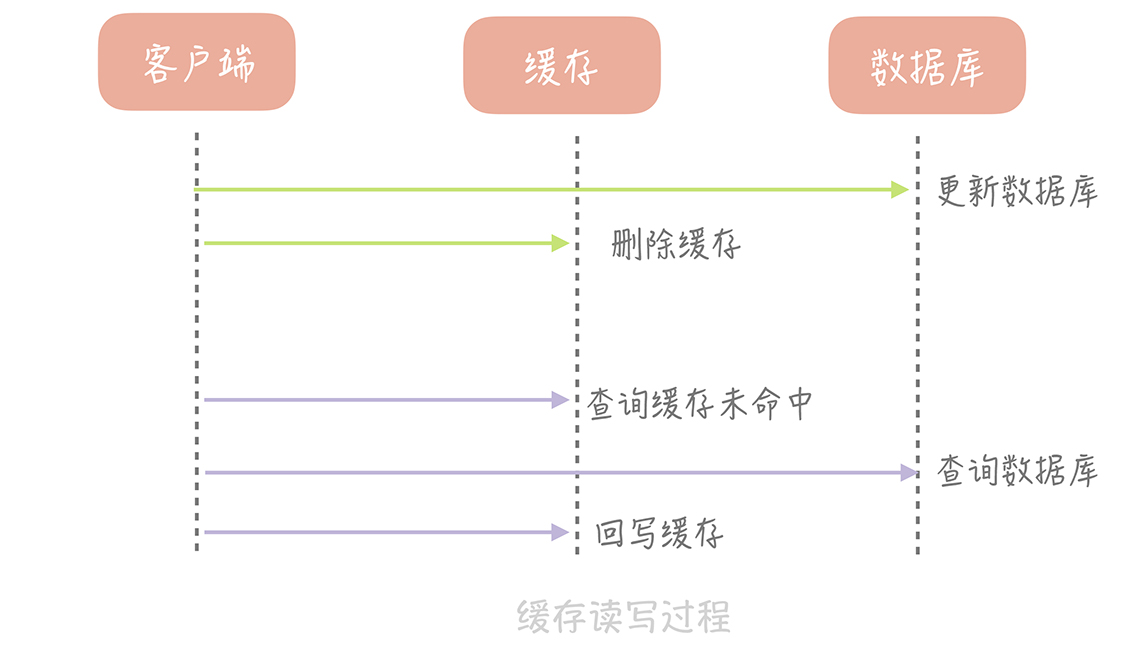
这个策略就是我们使用缓存最常见的策略,Cache Aside 策略(也叫旁路缓存策略),这个策略数据以数据库中的数据为准,缓存中的数据是按需加载的。它可以分为读策略和写策略,其中读策略的步骤是:
- 从缓存中读取数据;
- 如果缓存命中,则直接返回数据;
- 如果缓存不命中,则从数据库中查询数据;
- 查询到数据后,将数据写入到缓存中,并且返回给用户。
写策略的步骤是:
- 更新数据库中的记录;
- 删除缓存记录。
你也许会问了,在写策略中,能否先删除缓存,后更新数据库呢?答案是不行的,因为这样也有可能出现缓存数据不一致的问题,我以用户表的场景为例解释一下。
假设某个用户的年龄是 20,请求 A 要更新用户年龄为 21,所以它会删除缓存中的内容。这时,另一个请求 B 要读取这个用户的年龄,它查询缓存发现未命中后,会从数据库中读取到年龄为 20,并且写入到缓存中,然后请求 A 继续更改数据库,将用户的年龄更新为 21,这就造成了缓存和数据库的不一致。
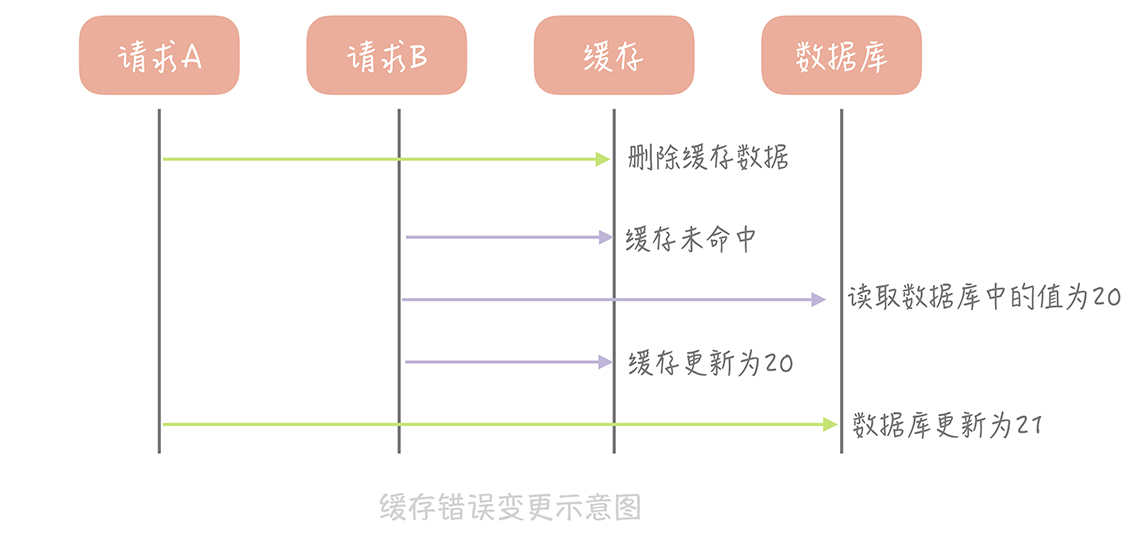
那么像 Cache Aside 策略这样先更新数据库,后删除缓存就没有问题了吗?其实在理论上还是有缺陷的。假如某个用户数据在缓存中不存在,请求 A 读取数据时从数据库中查询到年龄为 20,在未写入缓存中时另一个请求 B 更新数据。它更新数据库中的年龄为 21,并且清空缓存。这时请求 A 把从数据库中读到的年龄为 20 的数据写入到缓存中,造成缓存和数据库数据不一致。
不过这种问题出现的几率并不高,原因是缓存的写入通常远远快于数据库的写入,所以在实际中很难出现请求 B 已经更新了数据库并且清空了缓存,请求 A 才更新完缓存的情况。而一旦请求 A 早于请求 B 清空缓存之前更新了缓存,那么接下来的请求就会因为缓存为空而从数据库中重新加载数据,所以不会出现这种不一致的情况。
Cache Aside 策略是我们日常开发中最经常使用的缓存策略,不过我们在使用时也要学会依情况而变。比如说当新注册一个用户,按照这个更新策略,你要写数据库,然后清理缓存(当然缓存中没有数据给你清理)。可当我注册用户后立即读取用户信息,并且数据库主从分离时,会出现因为主从延迟所以读不到用户信息的情况。
而解决这个问题的办法恰恰是在插入新数据到数据库之后写入缓存,这样后续的读请求就会从缓存中读到数据了。并且因为是新注册的用户,所以不会出现并发更新用户信息的情况。
Cache Aside 存在的最大的问题是当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。如果你的业务对缓存命中率有严格的要求,那么可以考虑两种解决方案:
一种做法是在更新数据时也更新缓存,只是在更新缓存前先加一个分布式锁,因为这样在同一时间只允许一个线程更新缓存,就不会产生并发问题了。当然这么做对于写入的性能会有一些影响;
另一种做法同样也是在更新数据时更新缓存,只是给缓存加一个较短的过期时间,这样即使出现缓存不一致的情况,缓存的数据也会很快地过期,对业务的影响也是可以接受。

