
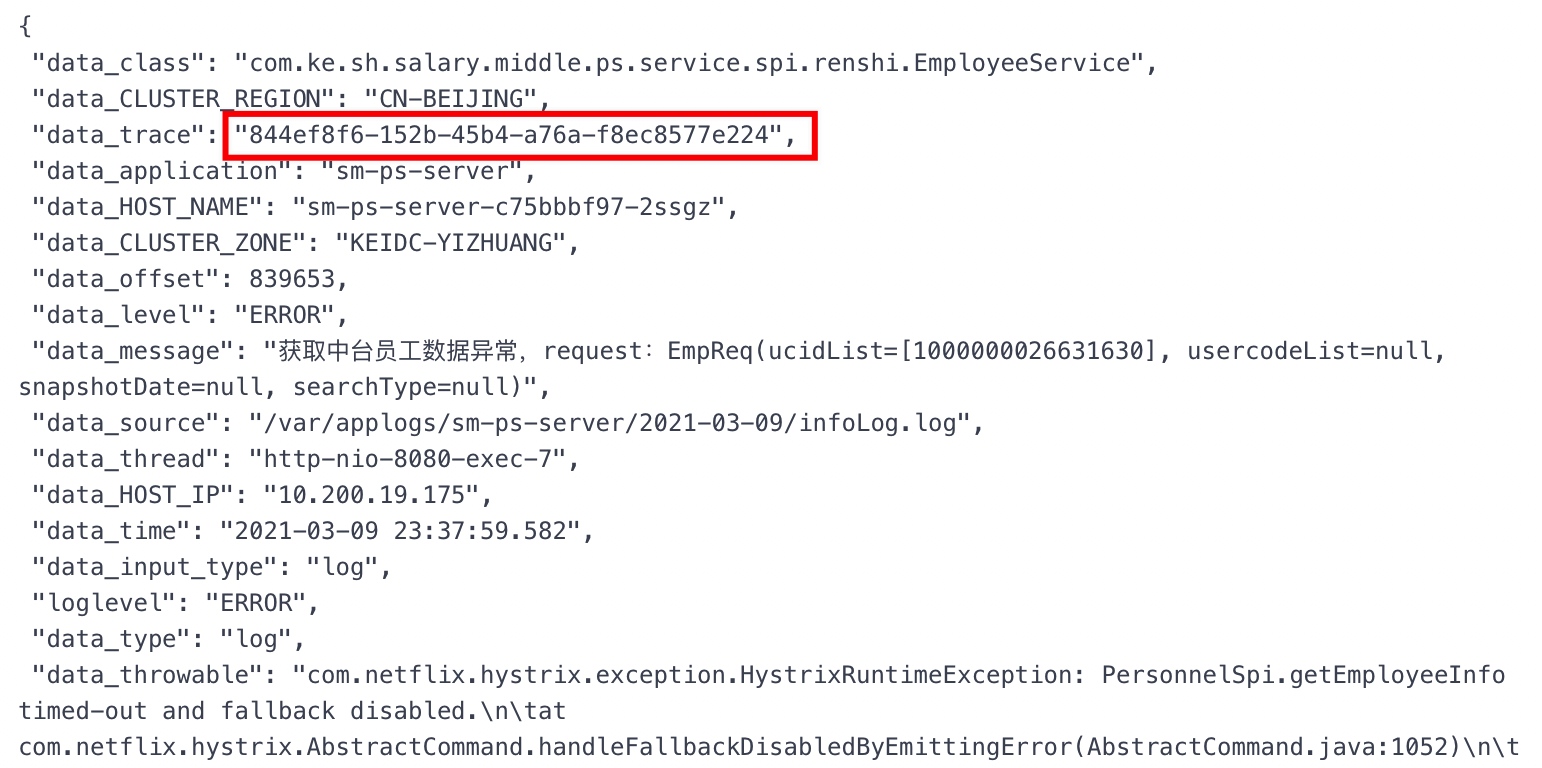
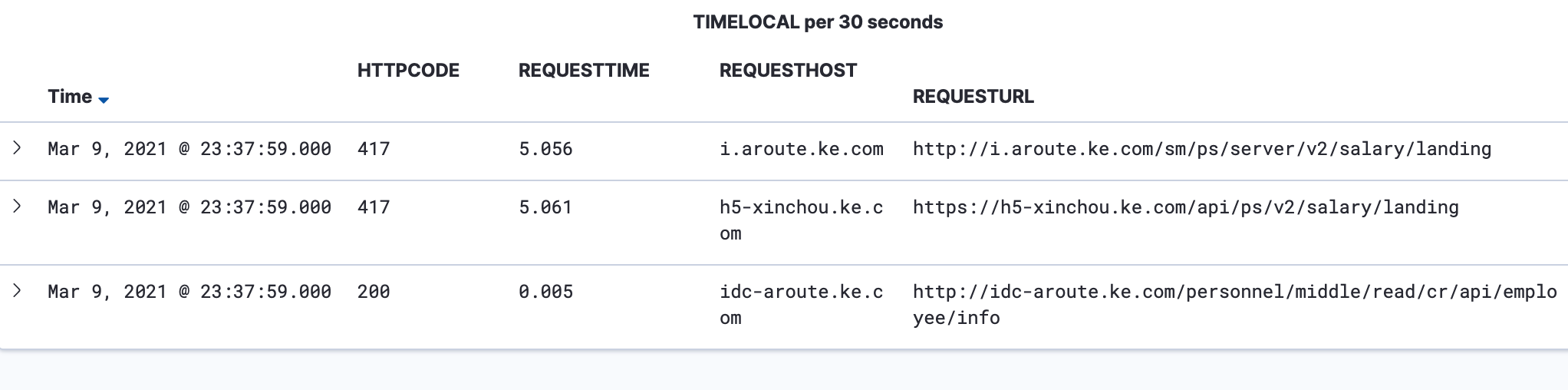
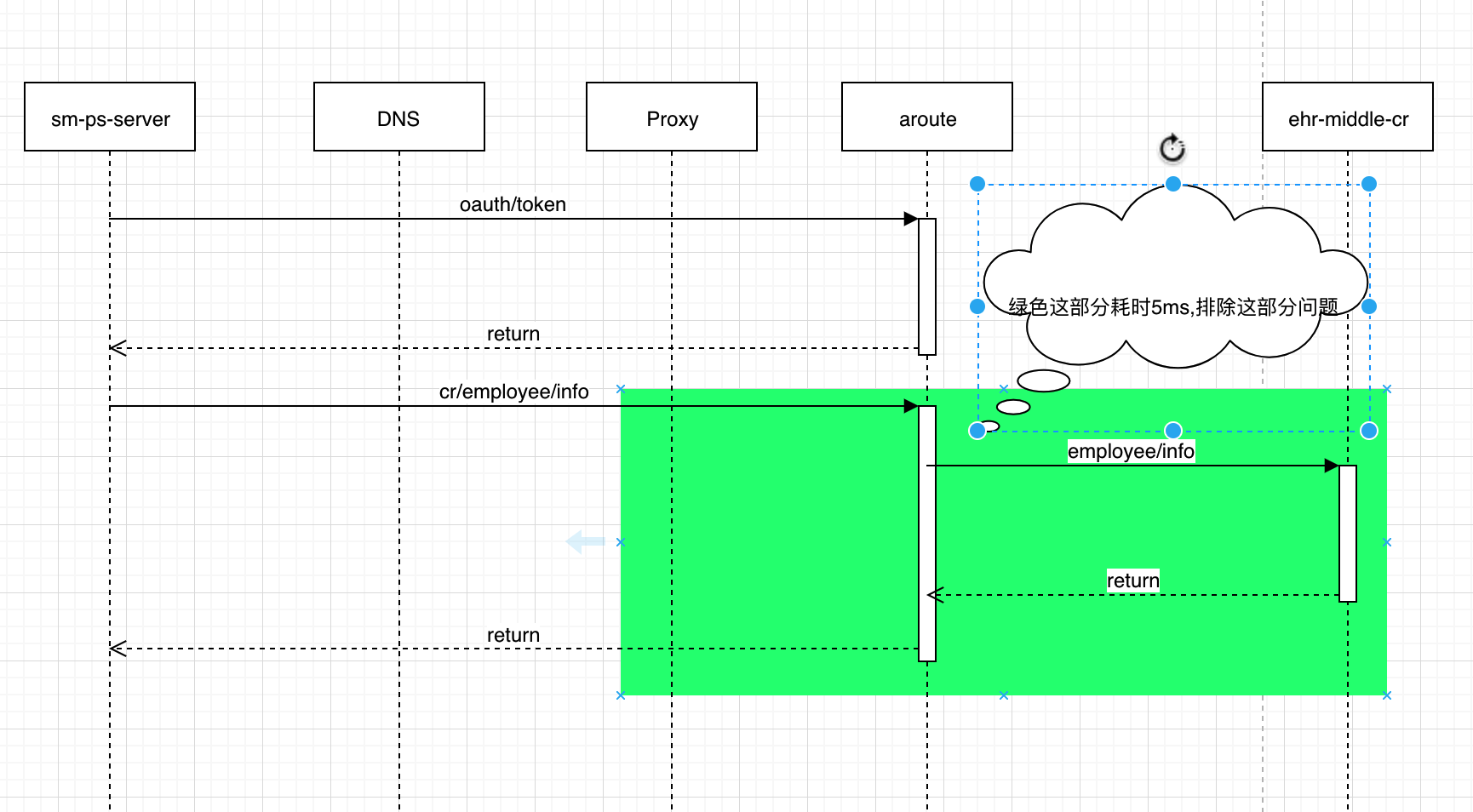
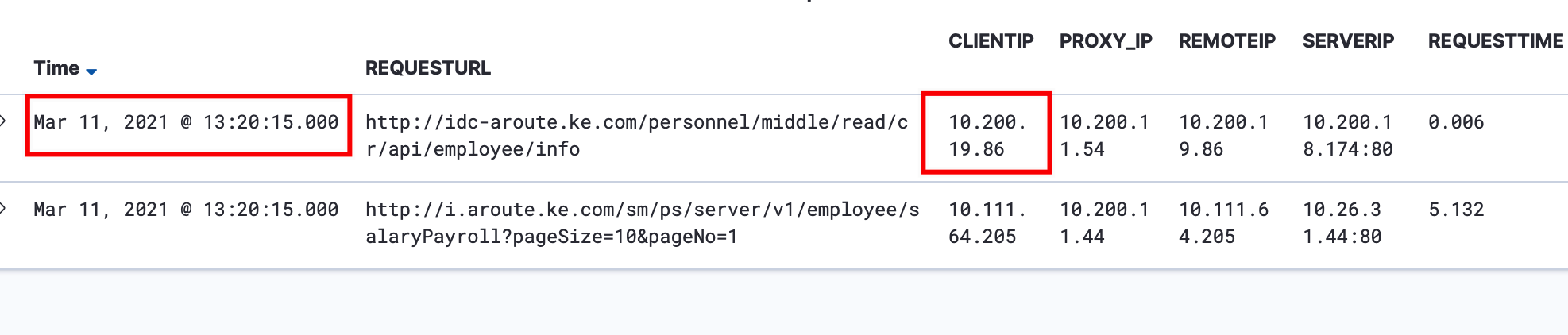
问题背景
java中对于精确小数,我们通常使用Bigdecimal进行存储,而mongo中是不存在Bigdecimal类型,对应的是Decimal128。
项目中使用mongo的地方,为了能够在插入mongo时将Bigdecimal转为Decimal128,查询时将Decimal128转回Bigdecimal,可以利用spring中的org.springframework.core.convert.converter.Converter。如下
1 |
|
1 |
|
在向容器中注入MongoTemplate时添加自定义的Converter后
我们就可以自由的对BigDecimal类型进行mongo存储和读取了。
真的没有问题了吗
当使用Map类型去接收Mongo查询结果时,上面的自定义Converter就会失效:
1 | return mongoTemplate.find(query, JSONObject.class, TABLE_NAME + year); |

经过代码调试,定位到MappingMongoConverter负责类型转换,其核心代码为:
1 | private Object getPotentiallyConvertedSimpleRead( Object value, Class<?> target) { |
由此发现使用Map<String,Object>接收结果时,target=Object.class ,而Decimal128属于Object子类,因此自定义Converter不生效
一波三折的解决方案-增加自定义Converter
由于Decimal128在下游系统中不存在,因此下游接收到数字被转换为Map类型且很难再次转换,因此准备从源头解决问题,修改类型转换逻辑,尝试将Decimal128转换为BigDecimal输出至下游,因此增加新的自定义Converter
1 |
|
结论是不行的,原因为子类判断优先自定义Converter转换:
1 | private Object getPotentiallyConvertedSimpleRead( Object value, Class<?> target) { |
第二折 自定义MappingMongoConverter
我们自定义转换逻辑,重写核心转换逻辑,使得自定义Converter优先转换,是否还有问题?
1 | private Object getPotentiallyConvertedSimpleRead( Object value, Class<?> target) { |
可以看到,当target=Object.class时,已经可以成功将Decimal128转换为BigDecimal,但是target=null时还是无法转换
第三折 解决嵌套转换问题
当对象存在嵌套时,MappingMongoConverter默认使用Map类型进行类型转换,此时target=null,造成了嵌套对象中的Decimal128对象并没有走到自定义Converter转换逻辑,因此再次修改代码:
1 | private Object getPotentiallyConvertedSimpleRead( Object value, Class<?> target) { |
至此使用Map接收Decimal128将被正确的转换至BigDecimal类型
总结与收获
此方案需要改动两处代码
- 增加Decimal128ToObjectConverter
- 自定义MappingMongoConverter
排查后收获:
- 除非上游改动代价太大,尽量在上游解决问题,不要抛给下游处理
- mongo-spring对于Map等动态类型转换支持不完善,尽量定义准确类型数据结构接收结果,重写MappingMongoConverter不是上策
- 固定位数小数也可转换为整数存储,来绕过数字精度和类型转换问题







![[项目] 多角色权限展示数据的一种实现](https://i.loli.net/2019/11/21/rK1i4uDs6WEzLc7.jpg)