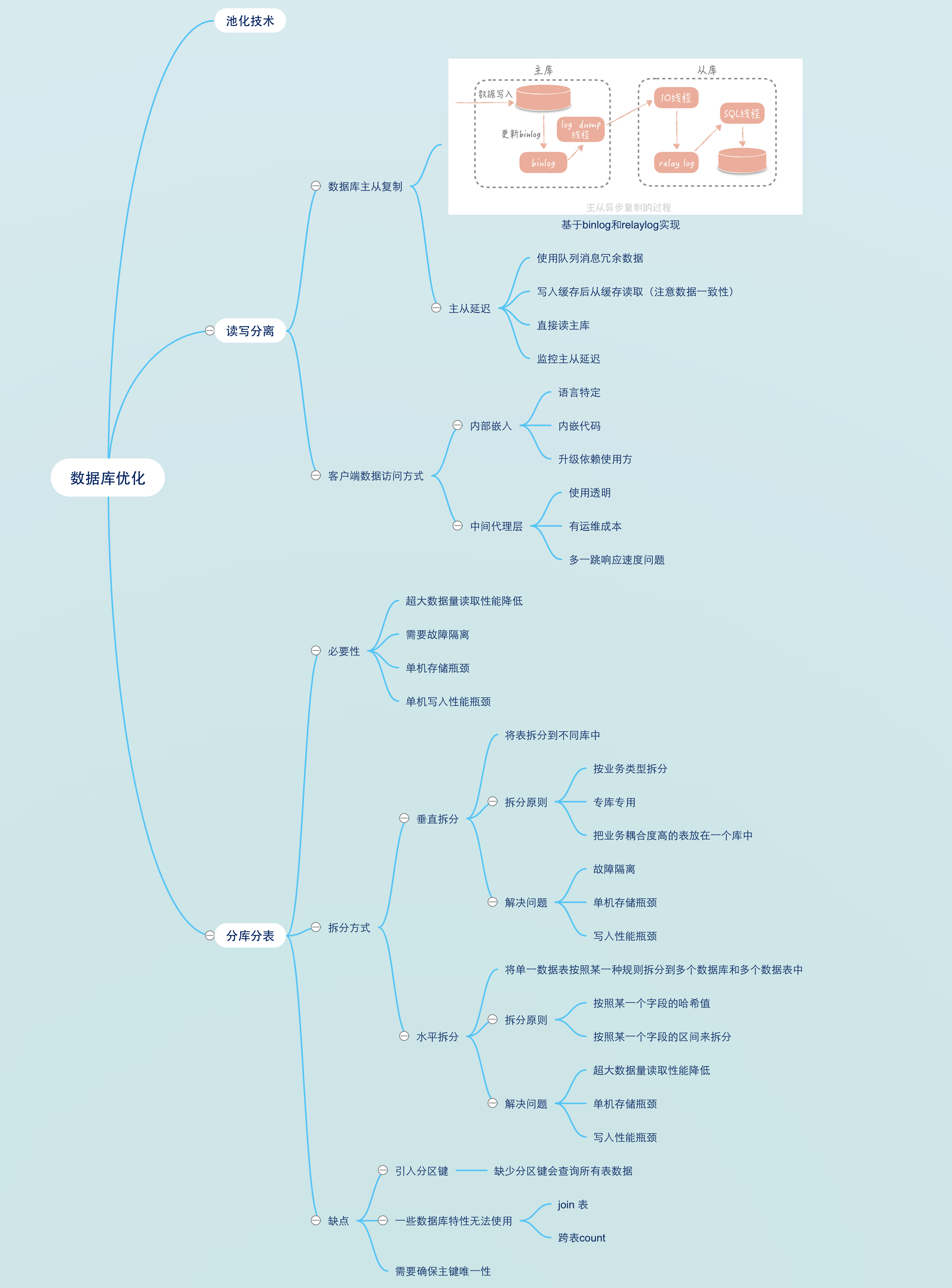
问题接口流程梳理
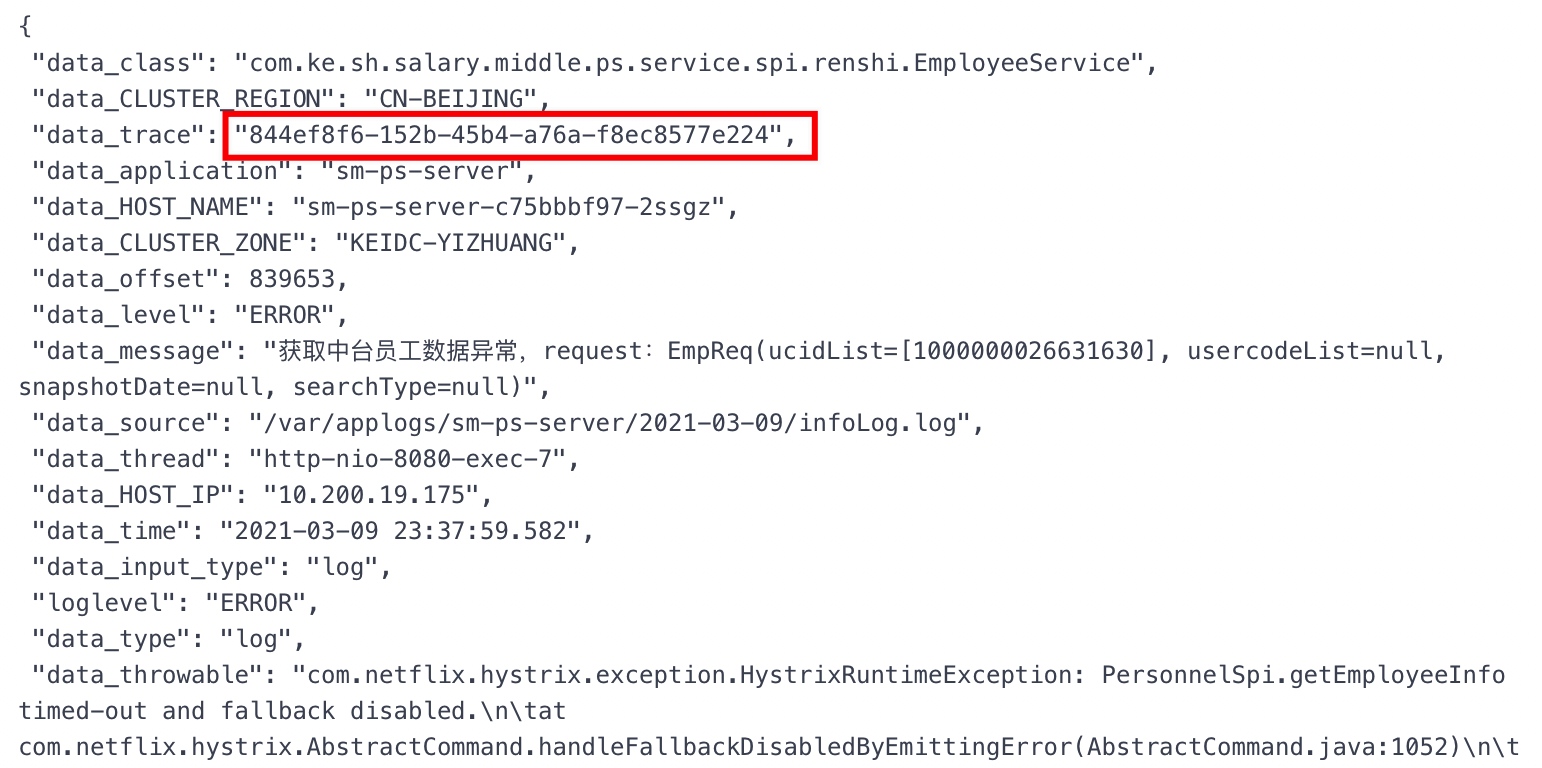
根据报错信息,可以看出调用PersonnelSpi.getEmployeeInfo超时,且调用时长超过5s
1 | com.netflix.hystrix.exception.HystrixRuntimeException: PersonnelSpi.getEmployeeInfo timed-out and fallback disabled |
先梳理出PersonnelSpi.getEmployeeInfo执行流程
- 先从网关获取oauthToken
- 通过网关调用人事cr/employee/info接口
目前可以得出结论是这两步耗时大于5s
排除人事接口问题
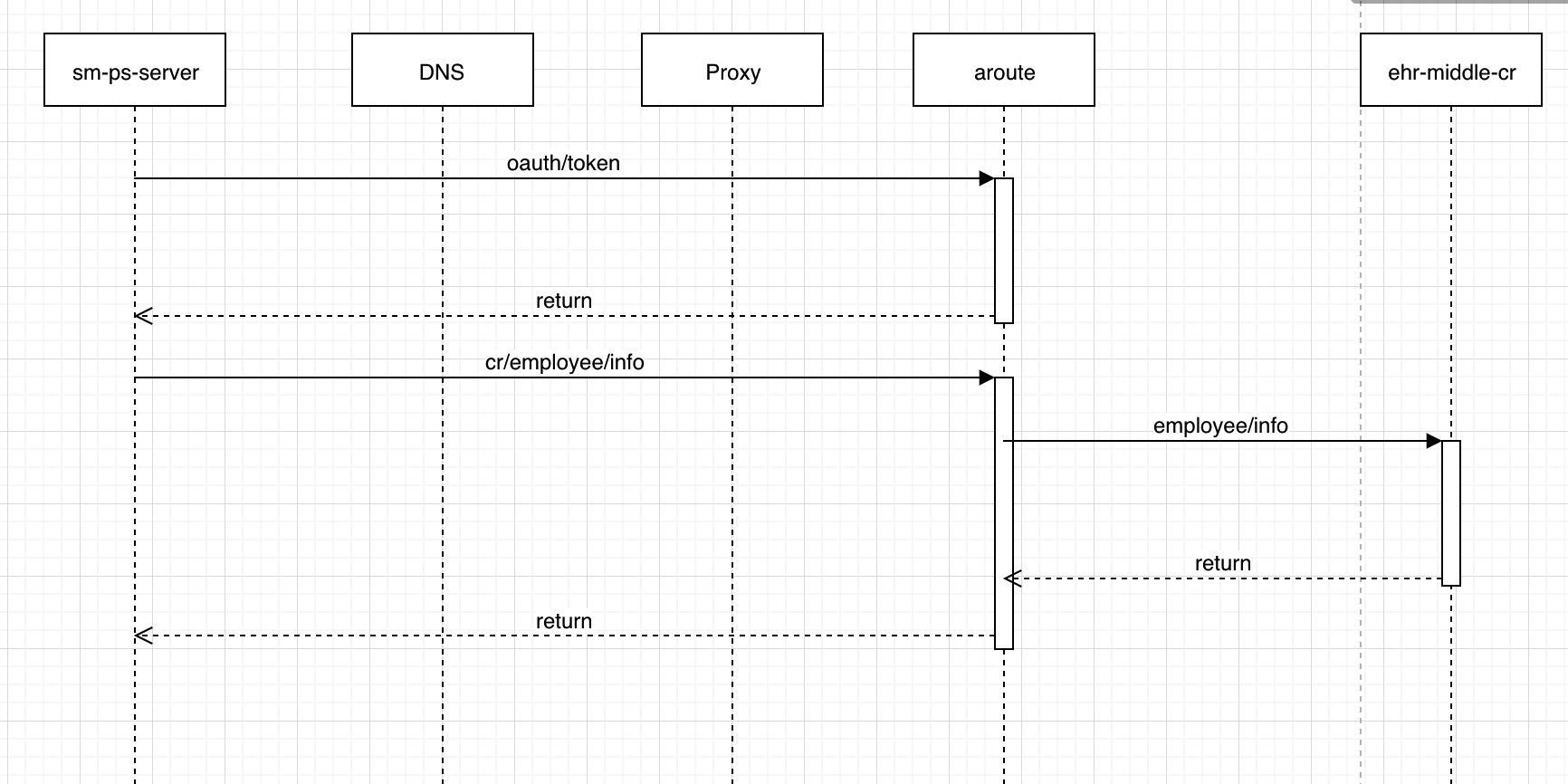
通过报警的data_trace字段,可以在fast7层中查询Proxy的access日志:
查询结果类似这样:
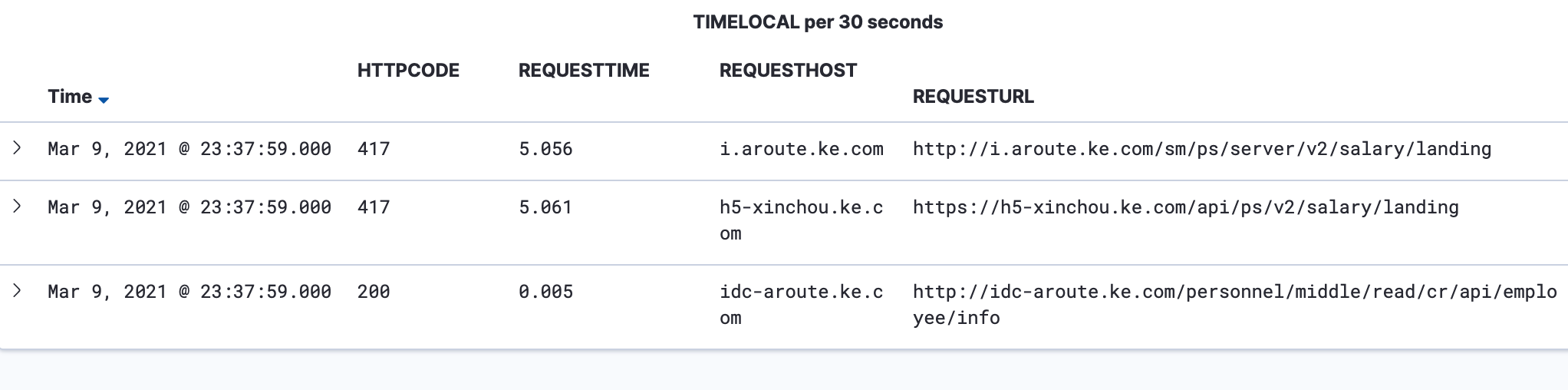
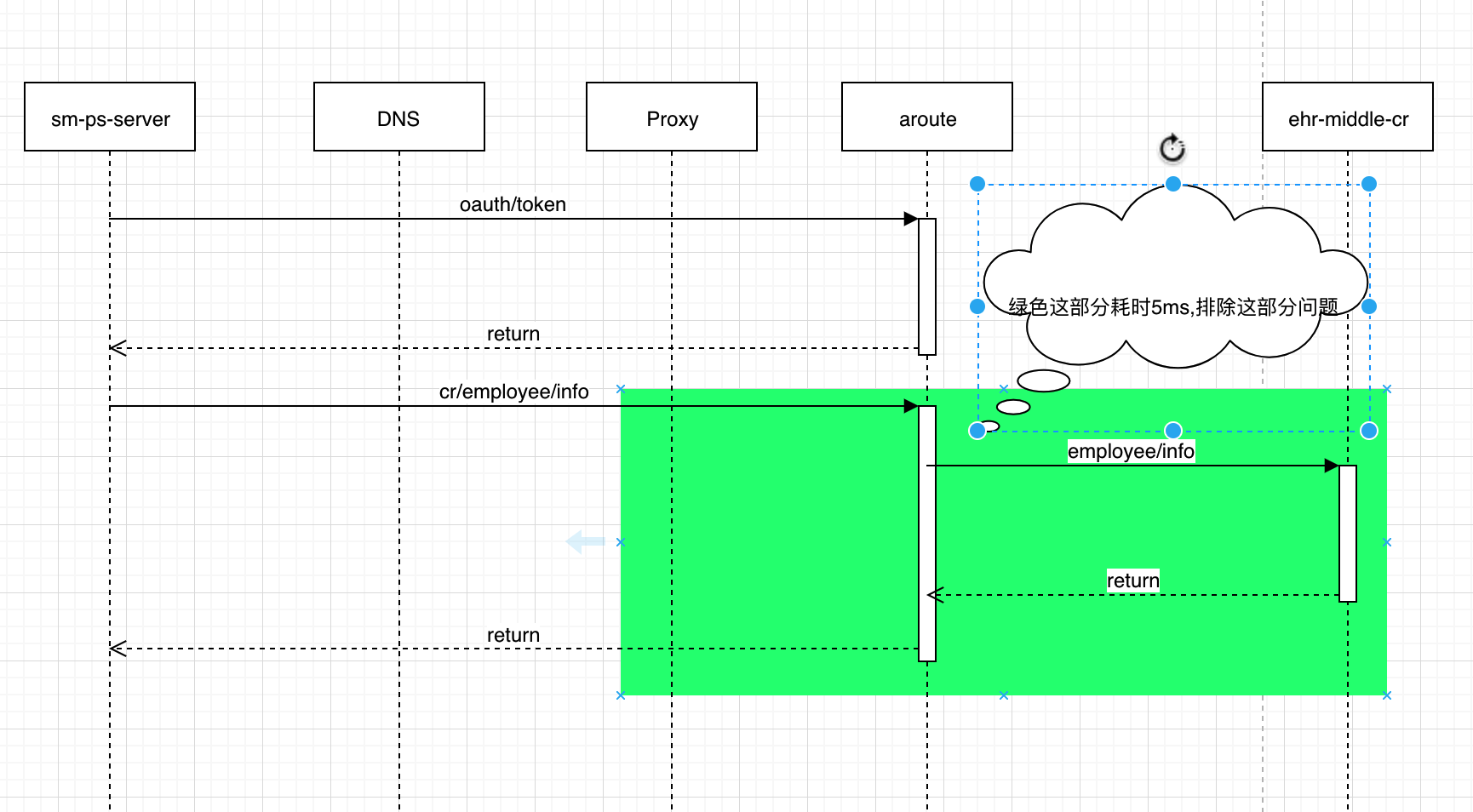
可以看到Proxy的accesslog中 Proxy返回cr/employee/info耗时5ms
排除oauth/token接口问题
通过时间+clientIP 筛选方式,找到fast7层日志中 oauth/token的日志
比如13:20:15 调用了cr/employee/info接口
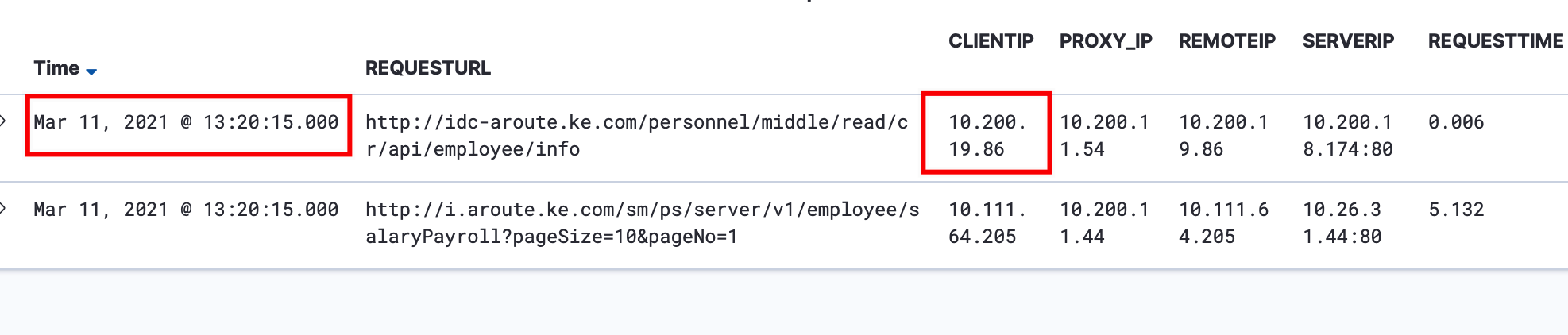
通过时间+clientIP+接口筛选,找到oauth/token的日志

从中可以得出两个结论:
- o auth/token接口耗时6ms
- o auth/tocken 和 cr/employee/info接口访问延迟在1s以内
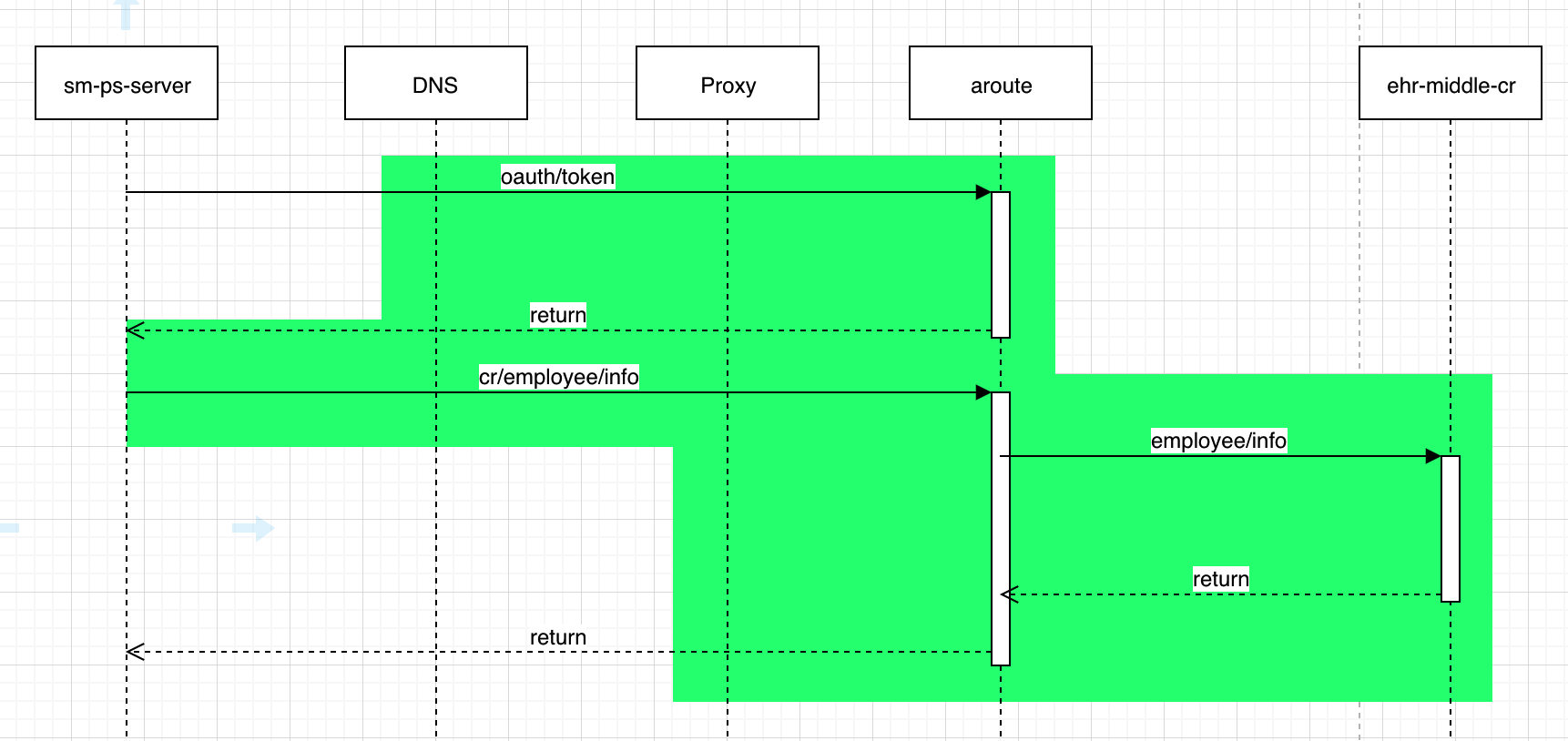
如图,绿色部分是有日志证明没有问题的部分
检查DNS问题
从上图可以看到,出现问题的部分只可能出现在sm-ps-server解析域名过程中
查看jk上DNS监控发现:idc-aroute.ke.com解析存在5s超时情况,但是发生超时时间和报错时间不一致
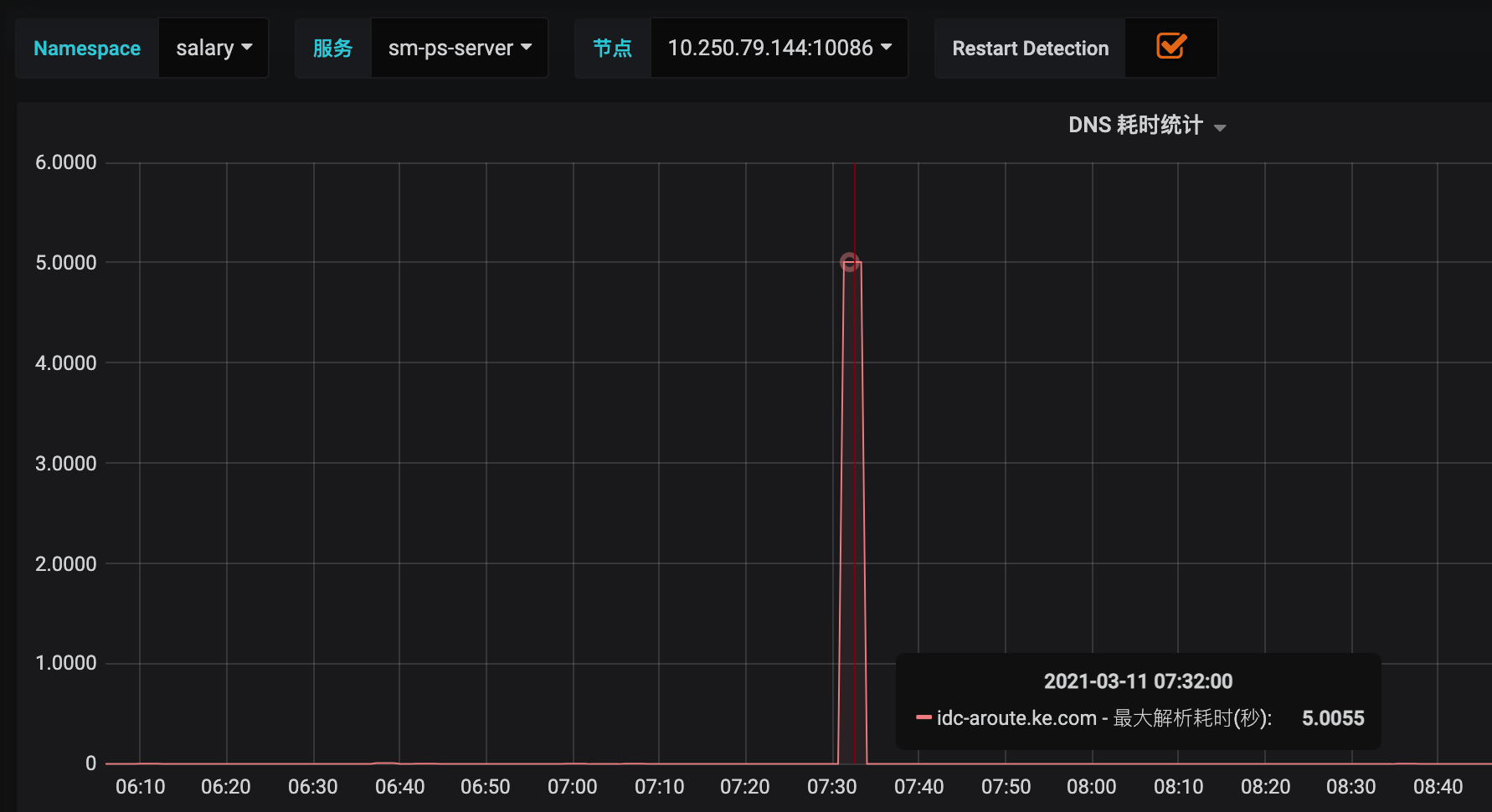
查看代码发现,jk的dns监控并不是调用接口解析域名耗时,而是定时任务去检查域名解析耗时,所以报错时DNS监控数据正常并不说明当时DNS解析没有超时
通过DNS监控可以得出结论: DNS解析超时5s的情况存在,并且会影响oauth client真实请求延迟5s,并导致接口超时
结论
- 优化oauthclient, 减少调用auth/token接口次数可以减少超时情况发生
- 解决在容器环境中DNS解析超时问题
更新
networkaddress.cache.ttl (default: -1)
Specified in java.security to indicate the caching policy for successful
name lookups from the name service. The value is specified as as integer
to indicate the number of seconds to cache the successful lookup.
A value of -1 indicates “cache forever”.networkaddress.cache.negative.ttl (default: 10)
Specified in java.security to indicate the caching policy for un-successful
name lookups from the name service. The value is specified as as integer to
indicate the number of seconds to cache the failure for un-successful lookups.
A value of 0 indicates “never cache”. A value of -1 indicates “cache forever”.
若DNS解析失败,会放入Negative Cache,默认缓存10秒(可调整/禁用),后续DNS解析直接返回UnknownHostException。也就是说,极端情况下,DNS解析失败会导致10秒不可用。所以建议禁用Negative Cache。







![[片段] 方法参数收集](https://i.loli.net/2020/03/27/DKo1cSZmtew2sTP.jpg)